Introduction
Recent advancements in large vision-language models (VLMs), such as GPT-4V and GPT-4o, have shown great promise in driving intelligent agent systems that operate within user interfaces (UI). However, these models' full potential remains underexplored in real-world applications, particularly when acting as general agents across diverse operating systems and applications with only vision input.
One of the main limiting factors has been the lack of a robust screen parsing technique capable of:
- Reliably identifying interactable icons within the user interface
- Understanding the semantics of various elements in a screenshot and accurately associating intended actions with corresponding screen regions
What is OmniParser?
OmniParser is a compact screen parsing module that converts UI screenshots into structured elements. It can be used with various models to create agents capable of taking actions on UIs. When combined with GPT-4V, it significantly improves the agent's ability to generate precisely grounded actions for interface regions.
How OmniParser Works
Curating Specialized Datasets
The development of OmniParser began with creating two key datasets:
Interactable icon detection dataset
- Curated from popular web pages
- Annotated to highlight clickable and actionable regions
Icon description dataset
- Associates each UI element with its corresponding function
- Serves as a key component for training models to understand element semantics
Fine-Tuning Detection and Captioning Models
OmniParser leverages two complementary models:
Detection model
- Fine-tuned on the interactable icon dataset
- Reliably identifies actionable regions within screenshots
Captioning model
- Trained on the icon description dataset
- Extracts functional semantics of detected elements
- Generates contextually accurate descriptions of intended actions
Benchmark Performance
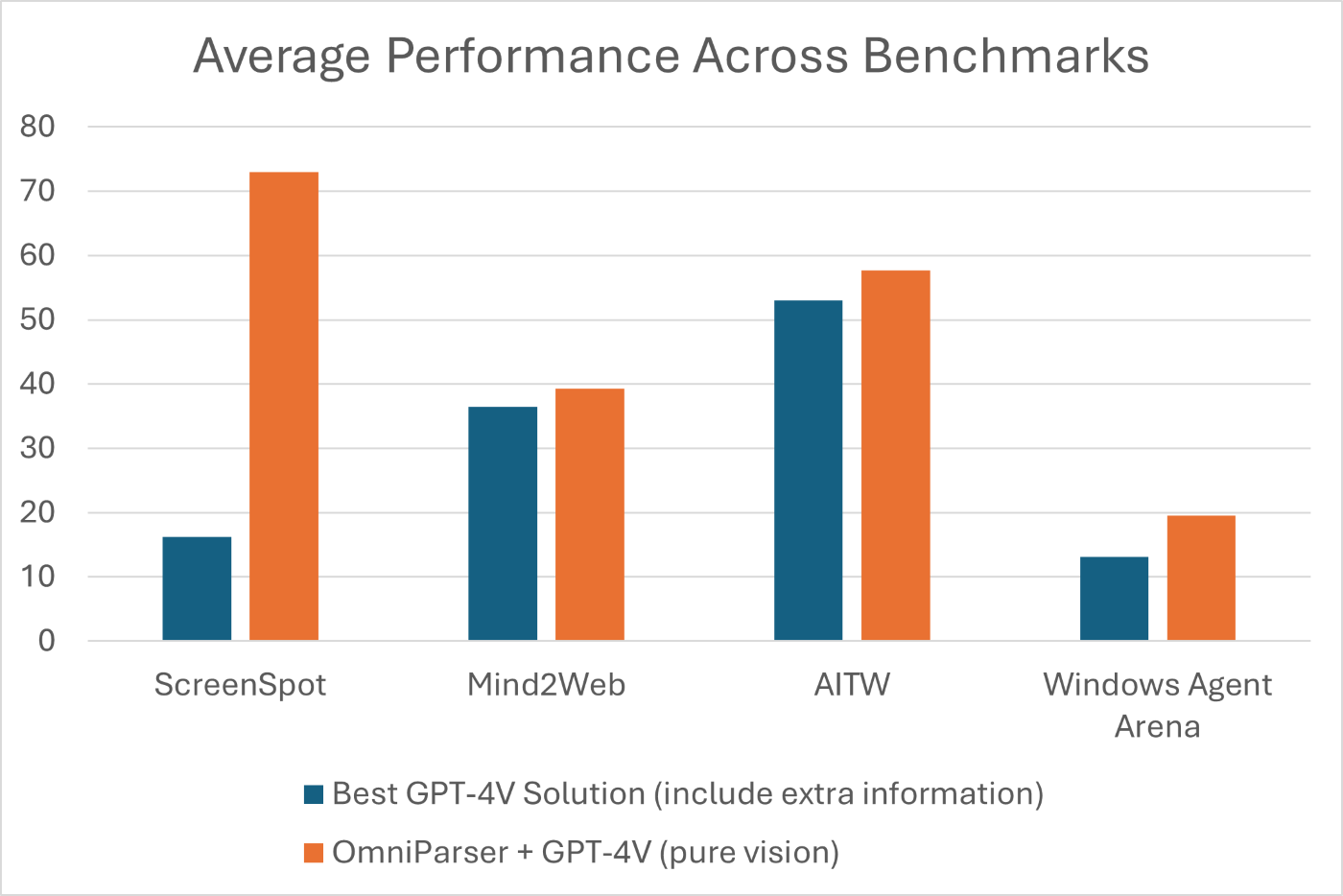
OmniParser has demonstrated impressive results across multiple benchmarks:
- Mind2Web: OmniParser + GPT-4V achieves better performance compared to GPT-4V agents using extra HTML information
- AITW: Outperforms GPT-4V augmented with specialized Android icon detection models trained with view hierarchy
- WindowsAgentArena: Achieved the best performance on this new benchmark
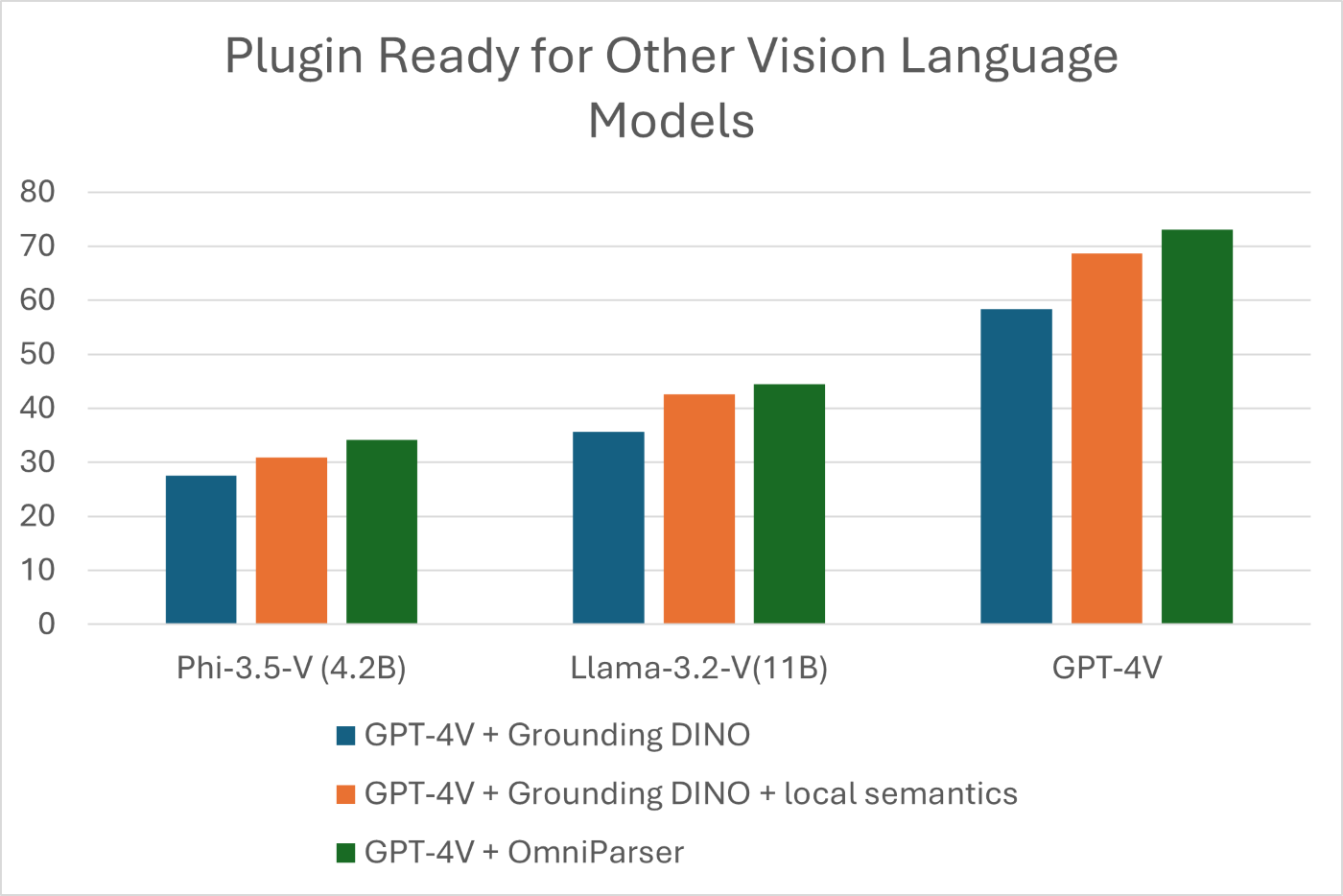
The system has also shown strong compatibility with other vision language models:
- Successfully integrated with Phi-3.5-V
- Compatible with Llama-3.2-V
Key Benefits
- Works across both PC and mobile platforms
- No dependency on extra information (HTML, Android view hierarchy)
- Serves as a general and easy-to-use tool
- Enhances the capabilities of existing vision language models
Conclusion
OmniParser represents a significant step forward in creating vision-based GUI agents that can operate across different platforms and applications. Its ability to work without platform-specific information while improving the performance of various vision language models makes it a valuable tool for researchers and developers in this field.
Call-to-Action
Interested in exploring OmniParser? The project is now publicly available on GitHub, along with detailed documentation about the training procedure.
Social Media Snippet: Discover OmniParser - Microsoft Research's breakthrough in vision-based GUI agents! #AI #Research #ComputerVision
Suggested Links: